大數據已成為驅動當今社會數字化、智能化轉型的核心引擎。它并非單一概念,而是一個由多重要素構成的復雜體系。要全面理解大數據,必須系統把握其構成、特點、技術、處理與應用這五個核心要素,而這一切的起點,正是數據采集。
一、 大數據構成:多樣來源的匯聚
大數據的構成是其物理基礎,指的是數據本身的來源與形態。它主要包含三大類數據:
1. 結構化數據:存儲在關系型數據庫中,具有清晰定義的格式,如表格、財務報表、客戶信息等。
2. 半結構化數據:雖不符合嚴格的數據庫表結構,但包含標簽或其他標記來分隔數據元素,如XML、JSON文件、電子郵件、HTML網頁等。
3. 非結構化數據:沒有預定義的數據模型,格式多樣,占當今數據總量的80%以上。例如,社交媒體文本、圖片、音頻、視頻、傳感器日志等。
這些數據共同構成了大數據龐大而復雜的“原材料”庫。
二、 大數據核心特點:4V+模型
大數據的價值與挑戰均源于其獨特特點,通常用“4V”模型概括:
1. Volume(體量大):數據量從TB級別躍升到PB乃至EB級別,規模巨大。
2. Variety(種類多):如上所述,數據類型極其豐富,涵蓋結構化、半結構化和非結構化數據。
3. Velocity(速度快):數據生成、流轉和處理的速度極快,要求實時或準實時響應,如金融交易、物聯網傳感數據流。
4. Value(價值密度低):海量數據中蘊含高價值的信息比例相對較低,需要通過深度挖掘才能提取出寶貴洞察。
業界還常補充Veracity(真實性),強調數據質量與可信度的重要性。
三、 大數據關鍵技術:支撐體系的基石
處理如此龐大的數據體量,離不開一系列關鍵技術的支撐:
1. 存儲技術:如分布式文件系統(如HDFS)、NoSQL數據庫(如MongoDB, Cassandra)、NewSQL數據庫等,用于低成本、高可靠地存儲海量異構數據。
2. 計算框架:以Hadoop的MapReduce和Apache Spark為核心,實現分布式并行計算,處理大規模數據集。
3. 資源管理與調度:如YARN、Kubernetes,負責高效管理和調度集群中的計算資源。
這些技術共同構成了大數據處理的基礎設施。
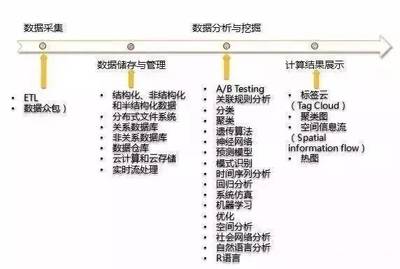
四、 大數據處理流程:從原始數據到智慧洞察
大數據的價值實現遵循一個完整的處理生命周期,主要包括:
- 數據采集與集成:這是整個流程的起點。通過ETL(提取、轉換、加載)工具、網絡爬蟲、傳感器、日志收集器(如Flume, Kafka)等技術,從各種異構源系統中匯聚數據。
- 數據存儲與管理:將采集到的數據存入合適的存儲系統,并進行有效組織和管理。
- 數據處理與分析:這是核心環節。包括數據清洗、轉換、統計分析、機器學習建模、數據挖掘等,以發現模式、關聯和趨勢。
- 數據可視化與解釋:將分析結果以圖表、儀表盤等直觀形式呈現,輔助決策。
五、 大數據應用:賦能千行百業
大數據技術已滲透到各個領域,創造巨大價值:
- 商業智能:客戶細分、精準營銷、需求預測、供應鏈優化。
- 金融服務:欺詐檢測、風險評估、算法交易。
- 醫療健康:疾病預測、個性化治療、藥物研發、醫療影像分析。
- 智慧城市:交通流量管理、公共安全監控、能源智能調度。
- 工業制造:預測性維護、工藝優化、質量控制。
聚焦起點:數據采集
正如您所特別指出的,數據采集是整個大數據價值鏈的首要環節和基石。沒有高質量、多渠道的數據采集,后續所有處理與分析都將是“無米之炊”。現代數據采集技術正朝著實時化(流數據采集)、智能化(邊緣計算預處理)和全面化(物聯網、社交網絡、業務系統全覆蓋)的方向發展。它確保原始數據能源源不斷地、可靠地匯入大數據平臺,為后續的價值挖掘奠定堅實基礎。
理解大數據,需要將其視為一個從構成(多樣數據源)出發,具備鮮明特點,依托核心技術,經過系統化處理流程,最終在廣泛應用場景中實現價值的完整生態系統。而數據采集,正是激活這個生態系統的第一把鑰匙。